
Olvasni a sorok között: amit a szerző nem akart volna elmondani








A cikk szerzője: Kapronczay Mór
Manapság a világ szinte minden területét forradalmasítja a rendelkezésünkre álló nagy mennyiségű adat, és azok kreatív feldolgozásai. Ilyen terület a közgazdaságtan is, ahol a szövegbányászat egy kifejezetten érdekes és viszonylag újdonságként ható területe a rendelkezésünkre álló adatok feldolgozásának. Segítségével akár olyan dolgokat is feltárhatunk, amelyeket a szerzők nem feltételenül akartak elmondani.
A szövegbányászat során nagy mennyiségű szöveget dolgoznak fel valamilyen – a sorok között – rejtőzködő válasz megtalálásának érdekében. Egy ilyen vizsgálatra jó példa egy bizonyos hashtagre érkezett tweetek feldolgozása. Ebben az esetben a sentiment analysis például arra keresi a választ, hogy a felhasználóknak milyen az attitűdje az adott témával kapcsolatban. Ha például sok negatív jelző hangzik el, feltehetőleg kevésbé viszonyulnak pozitívan az adott témához.
A sentiment analysis egy jelentős képviselője a Neticle cég, amit a Corvinuson nemrégiben végzett egyetemisták alapítottak. Ők remekül látták meg az üzleti lehetőséget a szövegbányászatban, és a közösségi médiát elemezve arról tudnak azonnali, tényalapú információval szolgálni, hogy az adott vállalat vagy termék megítélése hogyan viszonyul a versenytársakhoz.
Persze nem csak a tweetek hangulatát lehet elemezni. Az Economist negyedévente publikálja például „R-word index”-ét, amely a recession, (vagyis recesszió) szó előfordulásait vizsgálja a nagy lapokban (New York Times, Washington Post, stb.). Az alábbi ábrán az látható, a válság időszakaiban (sötéttel jelezve) az index jóval magasabb értéket vesz fel. Tehát a média szóhasználata jó indikátor arra, ami a gazdaságban történik.
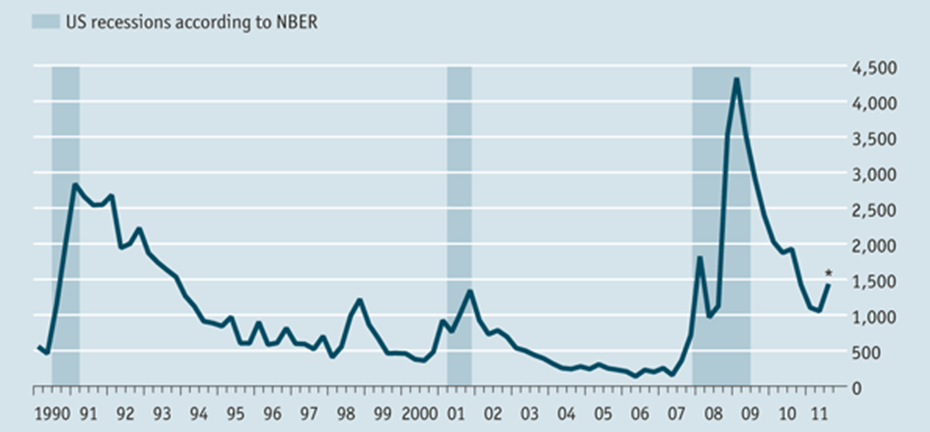
Az r-word index egy szó előfordulási gyakoriságát vizsgálja. Az említési gyakoriság vizsgálata számos érdekességet rejt még. Például megvizsgálják, hogy az orosz állami médiában milyen gyakran említenek politikusokat, és ezt akár a politikusok valós, mért világgazdasági jelentőségükkel összehasonlítva (pl.: országuk GDP-je, vagy lakossága) gyanakodhatunk a közvélemény befolyásolásának szándékára is.
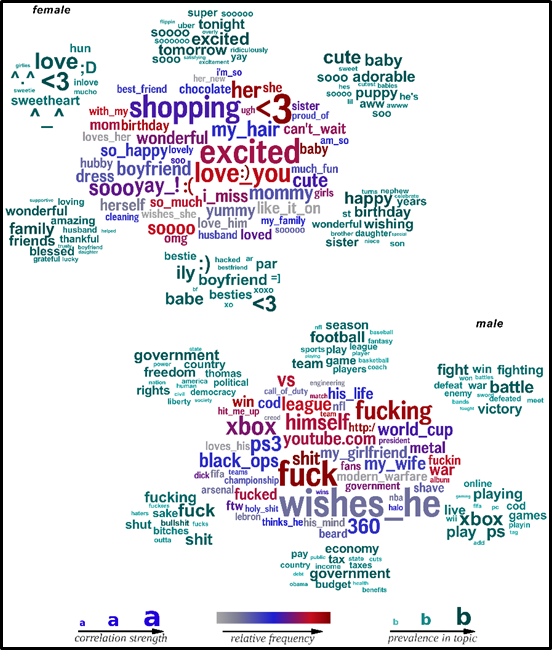
A szövegbányászat azonban ezen kívül is tartogat izgalmakat. Felhasználók facebook státuszainak elemzése legalább olyan jó személyiségjegyeik vizsgálatára (pl extrovertáltság vagy introvertáltság), mint az eddig használt pszichológiai tesztek. Az alábbi ábrán Scwartz és társai kutatása alapján a közösségi médiában a férfiak és a nők által leggyakrabban használt szavakat láthatjuk, igen beszédes ábrázolásban.
Az eddigiekből szinte egyenesen következik, hogy egy széleskörű elemzést akár a szerző azonosítására is használhatunk. Megállapítható például egy szakdolgozat szövegrészletéről is, hogy szinte biztosan nem az az ember írta, aki a dolgozat többi részét. Nemrég például J. K. Rowling Robert Galbraith álnéven kiadott krimijéről, a Kakukkszóról mutatták meg szövegbányászat segítségével, hogy a szerző azonos a Harry Potter könyvek szerzőjével.
Egy kutatásban szépirodalmi szerzők stílusát vizsgálták, amiből megállapítható, hogy a szöveg összetettségének statisztikai jellemzői (szavak átlagos szótag-, vagy karakterhossza, mondatok szóhossza, stb.) közel egyértelműen jelzik a szerzőt. A szövegekben használt szavakon alapuló TF-IDF módszertan pedig a vizsgált szerzők között tökéletesen jelezte, hogy ki az adott szöveg szerzője.
Látható tehát, hogy az általunk írt szövegek sokkal többet mondanak el, mint amit leírni szándékozunk. A sorok között olvasás képessége alatt azt szoktuk érteni, hogy a szöveg mögé nézünk. Vajon mit akart mondani a szerző? Milyen élethelyzetben írta a szöveget? A szövegbányászat segítségével viszont arra is fényt deríthetünk, amit a szerző nem akart elmondani.
